task 복구 방식
task 복구 방식
원문 : https://www.hashicorp.com/blog/resilient-infrastructure-with-nomad-restarting-tasks
Nomad가 종종 운영자 개입 없이 장애, 중단 상황, Nomad 클러스터 인프라의 유지 관리를 처리하는 방법 확인
1. Job과 task의 선언
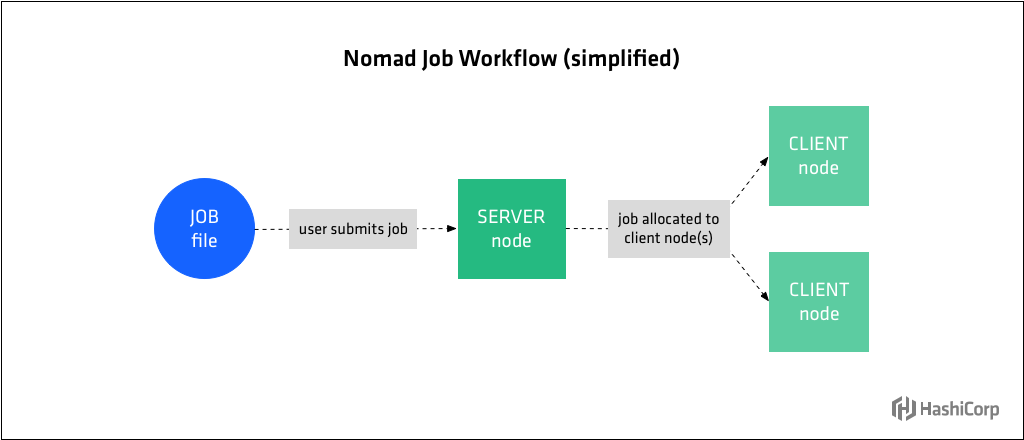
Job 은 실행 드라이버(Docker, Java, Exec 등)에 의해 Nomad 클라이언트 노드 에서 실행되는 명령, 서비스, 애플리케이션, 배치와 같은 형태입니다. task에서는 웹 애플리케이션, 데이터베이스 서버 또는 API와 같은 단기 배치 작업 또는 장기적으로 실행되는 서비스의 실행 방식을 정의 합니다.
redis를 실행하는 Job의 예는 다음과 같습니다.
job "example" {
datacenters = ["dc1"]
type = "service"
constraint {
attribute = "${attr.kernel.name}"
value = "linux"
}
group "cache" {
count = 1
task "redis" {
driver = "docker"
config {
image = "redis:3.2"
}
resources {
cpu = 500 # 500 MHz
memory = 256 # 256MB
}
}
}
}
Job을 작성할 때 작성자는 워크로드에 대한 리소스와 제약 조건을 정의할 수 있습니다. 제약 조건 은 커널 유형, 버전, OS와 같은 속성에 따라 노드의 워크로드 배치를 지정 및 제한합니다. 리소스 요구 사항에는 task 실행에 필요한 메모리, 네트워크, CPU 등이 포함됩니다.
Nomad는 Job 작성자가 실패하고 응답하지 않는 task 동작을 자동으로 다시 시작하고, 반복적으로 실패한 작업들을 다른 노드로 자동으로 재예약하는 전략을 지정할 수 있도록 하여 워크로드를 탄력적으로 만듭니다.
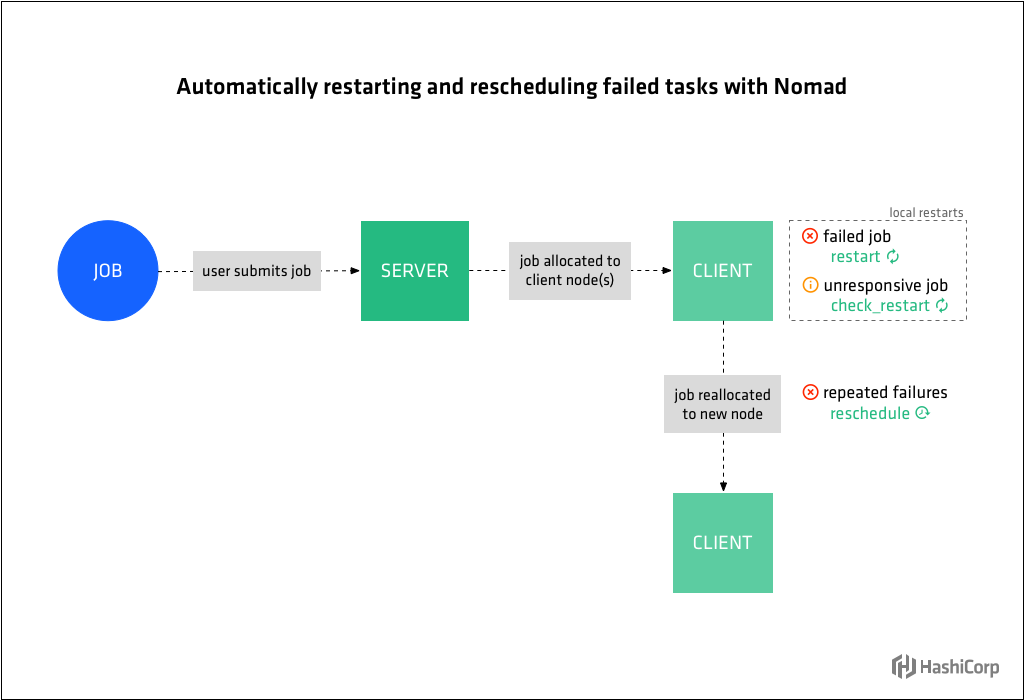
2. 실패한 task 재시작
Job의 실행 실패는 성공적으로 완료되지 않거나 오류 또는 리소스(CPU, Memory) 부족으로 인해 서비스가 실패하는 경우 발생할 수 있습니다.
Nomad는 Job 파일의 restart 절에 있는 지시문에 따라 동일한 노드에서 실패한 task를 다시 시작합니다. 운영자는 재시작 횟수인 attempts, 지연된 작업을 재시작하기 전에 Nomad가 기다려야 하는 시간인 delay, 시도된 재시작을 간격으로 제한하는 interval 시간을 지정합니다. failure인 mode를 사용하여 주어진 간격 내의 모든 재시작 시도가 소진된 후 task가 실행되지 않는 경우 Nomad가 수행해야 할 동작을 지정합니다.
기본 실패 모드는 Nomad가 Job을 다시 시작하지 않도록 지시하는 fail입니다. 이것은 몇 번의 실패 후에 성공할 가능성이 없는 멱등성이 아닌 실행 방식에 권장되는 값입니다. 다른 옵션은 Job을 다시 시작하기 전에 간격(interval)으로 지정된 시간만큼 기다리도록 Nomad에 지시하는 지연(delay)입니다.
다음 재시작 스탠자인 restart는 Nomad에게 30분 이내에 최대 2번의 재시작을 시도하도록 지시하고, 각 재시작 사이에 15초를 지연시키고 모두 소진된 후에는 더 이상 재시작을 시도하지 않습니다.
group "cache" {
...
restart {
attempts = 2
interval = "30m"
delay = "15s"
mode = "fail"
}
task "redis" {
...
}
}
다시 restart 동작은 버그, 메모리 누수, 기타 일시적인 문제에 대해 작업을 복원할 수 있도록 설계되었습니다. 이는 Nomad 외부에서 systemd, upstart 또는 runit과 같은 프로세스 관리자를 사용하는 것과 유사합니다.
3. 응답없는 task 재시작
또 다른 일반적인 시나리오는 프로세스 실행은 실패하지 않았지만 응답하지 않거나 비정상이 된 task를 다시 시작해야 하는 것입니다. Nomad는 check_restart 스탠자의 지시에 따라 응답하지 않는 Job을 다시 시작합니다. 이 동작은 Consul Health Check와 함께 작동합니다. 상태 확인이 제한 시간(limit)에 실패하면 Nomad가 Job을 재시작합니다. 값이 1이면 첫 번째 실패 시 다시 시작됩니다. 기본값인 0은 상태 확인 기반 재시작을 비활성화합니다.
실패는 연속적으로 발생해야 합니다. 한번이라도 정상적이였다면 카운트를 재설정하므로 통과 상태와 실패 상태를 번갈아 가는 경우 서비스가 다시 시작되지 않을 수 있습니다. 다시 시작한 후 상태 확인을 재개하기 위해 대기 기간을 지정하려면 grace를 사용하십시오. Nomad가 경고 상태를 통과 상태로 처리하고 다시 시작을 트리거하지 않도록 하려면 ignore_warnings = true로 설정하십시오.
다음 check_restart 정책은 상태 확인이 연속 3회 실패한 후 Redis 작업을 다시 시작하도록 Nomad에 지시합니다. task를 다시 시작한 후 90초 동안 대기하여 상태 확인을 재개하고 경고 상태(실패 포함)에서 다시 시작합니다.
task "redis" {
...
service {
check_restart {
limit = 3
grace = "90s"
ignore_warnings = false
}
}
}
기존 데이터 센터 환경에서 실패한 task를 다시 시작하는 것은 종종 작업자가 구성해야 하는 프로세스 관리자가 처리합니다. 비정상 task를 자동으로 감지하고 다시 시작하는 것은 더 복잡하며 모니터링 시스템이나 운영자 개입을 통합하기 위한 사용자 지정 스크립트가 필요합니다. Nomad를 사용하면 운영자 개입 없이 자동으로 발생합니다.
4. 실패한 task 다시 예약
지정된 수의 다시 시작한 후에 성공적으로 실행되지 않는 task는 하드웨어 오류, 커널 교착 상태 또는 기타 복구할 수 없는 오류와 같이 실행 중인 노드의 문제로 인해 실패할 수 있습니다.
운영자는 reschedule 스탠자를 사용하여 어떤 상황에서 실패한 task를 다른 노드로 일정을 변경해야 하는지 Nomad에게 알려줍니다.
Nomad는 이전에 해당 task에 사용되지 않은 노드로 일정을 변경하는 것을 선호합니다. restart 절과 마찬가지로 Nomad가 시도해야 하는 재스케줄 시도(attempts) 횟수, Nomad가 지연된 재스케줄 시도 사이에 대기해야 하는 시간(delay)과 간격(interval)으로 시도된 재스케줄 시도를 제한하는 시간을 지정할 수 있습니다.
또한 delay_function을 사용하여 초기 지연(delay) 후 후속 일정 변경 시도를 계산하는 데 사용할 함수를 지정합니다. 옵션은 constant, exponential, fibonacci입니다. 서비스 Job의 경우 피보나치(fibonacci) 스케줄링은 초기에 짧은 수명 중단에서 복구하기 위해 빠르게 일정을 재조정하는 반면 더 긴 중단 동안 이탈을 피하기 위해 속도를 늦추는 좋은 속성이 있습니다. exponential와 fibonacci 지연 함수를 사용할 때 max_delay를 사용하여 지연 시간의 상한선을 설정하고 그 이후에는 증가하지 않습니다. 무제한 재스케줄 시도를 활성화하거나 활성화하지 않으려면 unlimited를 true 또는 false로 설정합니다.
다시 스케줄링(reschedule)하는 동작을 완전히 비활성화하려면 attempts = 0 및 unlimited = false로 설정합니다.
다음 reschedule 스탠자는 Nomad에게 task group 일정을 무제한으로 다시 예약하고 후속 시도 사이의 지연을 기하급수적으로 늘리도록 지시합니다. 시작 지연은 30초에서 최대 1시간입니다.
group "cache" {
...
reschedule {
delay = "30s"
delay_function = "exponential"
max_delay = "1hr"
unlimited = true
}
}
재스케줄 스탠자는 모든 노드에서 실행되기 때문에 시스템 작업에 적용되지 않습니다.
Nomad 버전 0.8.4부터는 배포 중에 reschedule 스탠자가 적용됩니다.
기존 데이터 센터에서 노드 오류는 모니터링 시스템에 의해 감지되고 운영자에게 경고를 트리거합니다. 그런 다음 운영자는 장애가 발생한 노드를 복구하거나 워크로드를 다른 노드로 마이그레이션하기 위해 수동으로 개입해야 합니다. reschedule 기능을 통해 운영자는 가장 일반적인 실패 시나리오에 대한 계획을 세울 수 있으며 Nomad는 수동 개입의 필요성을 피하면서 자동으로 응답합니다. Nomad는 합리적인 기본값을 적용하므로 대부분의 사용자는 다양한 재시작 매개변수에 대해 생각할 필요 없이 로컬 재시작 및 일정 변경을 얻을 수 있습니다.
정리
운영자는 restart 절을 사용하여 실패한 작업에 대한 Nomad의 동일 노드에 대한 로컬 재시작 전략을 지정합니다. Consul 및 check_restart 스탠자와 함께 사용하면 Nomad는 restart 매개변수에 따라 응답하지 않는 작업을 동일 노드에서 다시 시작합니다. 운영자는 reschedule 절을 사용하여 실패한 Job을 다른 노드에 다시 예약하기 위한 Nomad의 전략을 지정합니다.