NoSQL 데이터베이스 - MongoDB
26. 3. 8.약 9 분
NoSQL 데이터베이스 - MongoDB
원문 : https://www.mongodb.com/resources/basics/databases/nosql-explained
NoSQL 데이터베이스인 MongoDB를 통해 NoSQL의 다양한 유형과 활용에 대해 설명하는 내용입니다. 문서 지향형, 키-값, 와이드-칼럼, 그래프 등 다양한 NoSQL 데이터베이스의 특징과 역사를 다루고 있습니다. 또한 MongoDB를 활용한 NoSQL 쿼리 튜토리얼을 제공하며 Multi-record Transactions에 대한 내용도 다룹니다.
1.️ NoSQL 데이터베이스
- NoSQL 데이터베이스는 일반적으로 비 관계형 데이터베이스를 나타냅니다.
- NoSQL 데이터베이스는 자료를
자연스럽고 유연하게저장한다는 특징을 갖습니다. - SQL은
쿼리 언어이고,NoSQL은 데이터베이스 관리 방법을 의미합니다.
2. NoSQL 데이터베이스 유형
- 시간이 흐름에 따라 네 가지 주요 NoSQL 데이터베이스 유형이 나타났습니다.
- Document databases : MongoDB, Couchbase
- Key-Value stores : Redis, Amazon DynamoDB
- Wide-Column stores : HBase, Cassandra, Scylla, Excel, Google Sheet
- Graph databases : Neo4J, Amazon Neptune, AllegroGraph
- Multi-model databases : CosmosDB, ArangoDB
2.1 문서(Document) 지향형 데이터베이스
- 문서 지향형 데이터베이스는 JSON (JavaScript Object Notation) 객체와 유사한 형태의 문서에 데이터를 저장합니다.
- 각 문서는 필드와 값의 쌍을 포함
- 값은 문자열, 숫자, 부울린, 배열 또는 다른 객체와 같이 다양한 유형
- 데이터 모델이 반구조화되거나 비구조화된 데이터 세트에 적합
- 중첩 구조를 지원하여 복잡한 관계나 계층적 데이터를 표현에 유리
{
"_id": "12345",
"name": "foo bar",
"email": "foo@bar.com",
"address": {
"street": "123 foo street",
"city": "some city",
"state": "some state",
"zip": 123456
},
"hobbies": ["music", "guitar", "reading"]
}
2.2 Key-Value(K/V) 저장소
- K/V 저장소는 단순하게 각 항목을 키와 값으로 표현합니다.
- 캐싱 및 세션 관리에 사용되며 인메모리에 데이터를 저장하여 높은 성능의 읽기와 쓰기를 제공합니다.
user-12345 = {"name": "foo bar", "email": "foo@bar.com", "designation": "software developer"}
2.3 wide-column 저장소
- wide-column 저장소는 테이블, 행, 컬럼에 데이터를 저장합니다.
- 전통적인 SQL 데이터베이스와 달리, wide-column 저장소는 유연하여 다른 행이 다른 컬럼 집합을 갖을 수 있습니다.
- 컬럼 압축 기술을 사용하여 저장 공간을 줄이고 성능을 향상시킬 수 있습니다.
- 희소하고 넓은 데이터를 효율적으로 검색할 수 있습니다.
| name | id | dob | city | |
|---|---|---|---|---|
| Foo bar | 12345 | foo@bar.com | Some city | |
| Carn Yale | 34521 | bar@foo.com | 12-05-1972 |
2.4 Graph 데이터베이스
- 노드와 엣지 형태로로 데이터 저장합니다.
- 노드는 일반적으로 사람, 장소, 물건(명사)과 같은 정보를 저장하며, 엣지는 노드 간 관계에 대한 정보를 저장합니다.
- 관계나 패턴이 처음에는 명확하지 않은 경우에 사용됩니다. (Social networks, Network diagrams 등에 사용)
- MongoDB는 집계 파이프라인의 $graphLookup 단계를 사용하여 그래프 데이터를 다루기도 합니다.
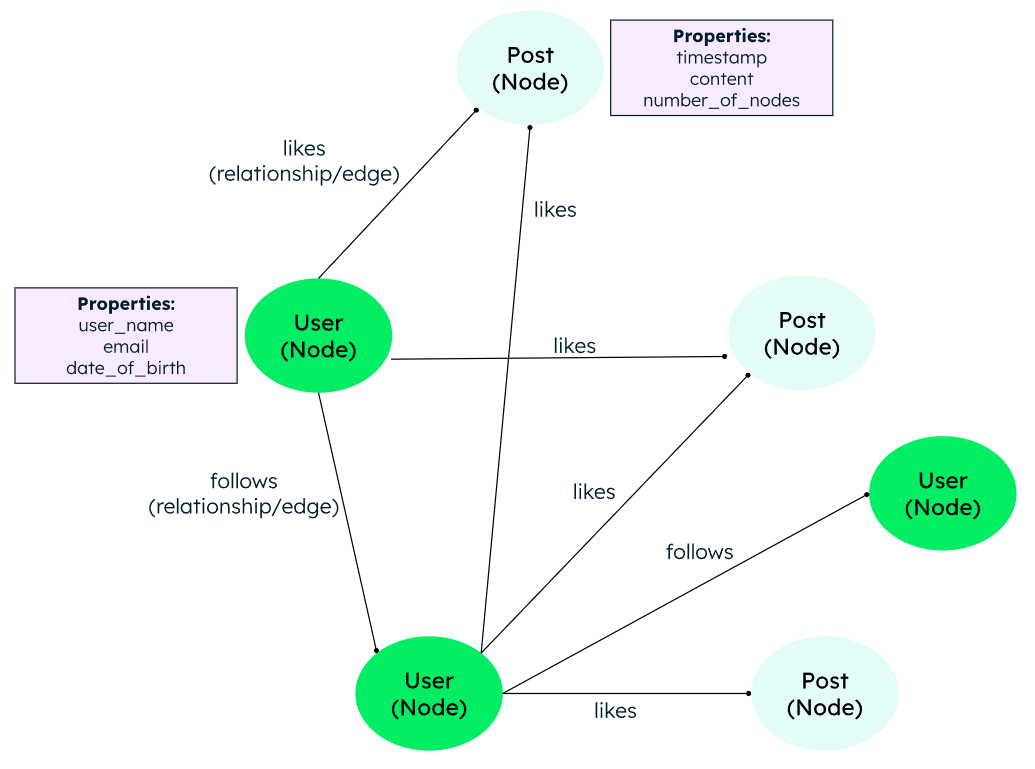
2.5 Multi-model(다중 모델) 데이터베이스
- 둘 이상의 유형의 NoSQL 데이터 모델을 지원하는 데이터베이스를 지칭합니다.
3. NoSQL 유형의 비교
| Feature | Key-Value Store | Document Database | Wide-Column Store | Graph Database |
|---|---|---|---|---|
| Data Visualization Support | Basic support for data visualization | Basic support for data visualization | Basic support for data visualization | Basic support for data visualization |
| Access Control | Basic authentication, limited access control | Role-based access control, encryption at-rest, encryption in transit, and in use | Role-based access control (RBAC), encryption at rest | Role-based access control (RBAC), encryption at rest, in transit |
| Online Data Archival | Limited support for online data archival | Automatic online data archival | Limited support for online data archival | Limited support for online data archival |
| Search Capabilities | Limited search capabilities | Full-text search, vector search | Limited search capabilities | Limited search capabilities |
| Data Manipulation | Basic CRUD operations, limited data manipulation capabilities | Advanced query and data manipulation capabilities | Data manipulation and CRUD capabilities | Supports advanced graph traversal and manipulation operations |
| Data Structure | Stores any type of data | Stores JSON/BSON data | Columns and rows matrix | Nodes, edges, and relationships |
| Use Cases | General purposes | Suited for time-series, IoT analytics, real-time analytics | Suited for time-series data, IoT analytics | Well-suited for graph analytics |
| Scalability and Consistency | Horizontal scalability and eventual consistency | Horizontal scalability and eventual consistency | Horizontal scalability and eventual consistency | Horizontal scalability and eventual consistency |
| Indexing | Simple indexes | Indexes on fields | Secondary indexes | Indexes on nodes/edges |
| Query Capability | Limited by key | Rich querying capability | Limited by columns | Specialized graph query |
| Schema | Schemaless | Flexible schema | Flexible schema | Flexible schema |
| Data Format | Simple key-value pairs | JSON/BSON documents | Column and row families | Nodes, edges, and relationships |
4. NoSQL 데이터베이스의 역사
- NoSQL 데이터베이스는 2000년대 후반에 스토리지 비용 감소와 함께 등장했습니다. 데이터 중복을 피하기 위해 복잡하고 관리하기 어려운 데이터 모델을 탈피하는 시기였습니다.
- 다중 모델 데이터베이스는 여러 유형의 NoSQL 데이터 모델을 지원하여 개발자가 애플리케이션 요구에 따라 선택할 수 있으며, 예로 CosmosDB와 ArangoDB가 있습니다. Google의 BigTable에 대한 논문이 발표된 2000년대 초반과, MongoDB와 CouchDB의 출현이 본격화 된 2009년은 NoSQL 데이터베이스가 크게 증가한 주요 시기였습니다.
- 2010년대에는 다양한 유형의 NoSQL 데이터베이스가 등장했고, 클라우드 컴퓨팅의 인기가 높아지면서 개발자들은 애플리케이션과 데이터를 공용 클라우드에 호스팅하기 시작했으며, 데이터를 여러 서버와 지역에 분산시켜 애플리케이션의 복원력을 높이고 확장성을 제공하려는 시도가 증가하였습니다.
5. NoSQL 데이터베이스 기능
NoSQL 데이터베이스에는 일반적으로 다음과 같은 기능이 있습니다:
- 분산 컴퓨팅
- 스케일링
- 유연한 스키마 및 풍부한 쿼리 언어
- 개발자의 사용 편의성
- 파티션 청크
- 고 가용성
6. RDBMS와 NoSQL 데이터베이스의 차이점
- NoSQL 데이터베이스에서 데이터 모델링 방식은 다중 레코드 트랜잭션의 필요성을 제거할 수 있습니다.
- 관계형 모델과 문서 저장소에 사용자 및 취미 정보를 저장하는 예제를 고려하면, 관계형 데이터베이스에서는 두 테이블의 레코드를 업데이트하기 위해 트랜잭션이 필요하지만 문서 저장소에서는 단일 문서 업데이트로 가능합니다.
- 문서 저장소에서는 다중 레코드 트랜잭션이 필요하지 않습니다.

| 특징 | NoSQL | RDBMS |
|---|---|---|
| 데이터 모델링 | NoSQL 데이터베이스 유형 (예 : Key/Value, Document, Graph, Wide-Column)에 따라 모델이 반 구조화 및 비 구조화 된 데이터에 적합하도록합니다. | 테이블 형식 데이터 구조를 사용하며 데이터는 행과 열 세트로 표시되므로 모델이 구조화 된 데이터에 적합합니다. |
| 스키마 | Key/Value, Document, Graph, Wide-Column가 다른 유형의 데이터를 포함 할 수있는 유연한 스키마를 제공합니다. 유연성으로 인해 필요한 경우 스키마를 쉽게 변경할 수 있습니다. | 테이블 형식 데이터 구조를 사용하며 데이터는 행과 열 세트로 표시되므로 모델이 구조화 된 데이터에 적합합니다. |
| 쿼리 언어 | 사용 된 NoSQL 데이터베이스 유형에 따라 다릅니다. 예를 들어 MongoDB에는 MQL, Neo4J는 Cypher를 사용합니다. | 대부분 구조화 된 쿼리 언어 (SQL)를 사용합니다. |
| 확장성 | 수직 및 수평 스케일링을 위해 설계되었습니다. | 수직 스케일링을 위해 설계되었습니다. 그러나 수평 스케일링을 위해 제한된 기능을 확장 할 수 있습니다. |
| 데이터 관계 | 관계는 중첩, 명시 적 또는 암시적일 수 있습니다. | 관계는 외래 키를 통해 정의되며 조인을 사용하여 액세스합니다. |
| 트랜젝션 유형 | ACID 또는 BASE-compliant | ACID를 준수 |
| 적합성 | 실시간 처리, 빅 데이터 분석 및 분산 환경에 적합합니다. | 읽기 및 트랜잭션 워크로드에 적합합니다. |
| 데이터 일관성 | 높은 데이터 일관성을 제공합니다. | 대부분의 경우 일관성을 제공합니다. |
| 분산 컴퓨팅 | NoSQL을 도입 한 주된 이유 중 하나는 분산 컴퓨팅 때문이며 NoSQL 데이터베이스는 샤딩, 복제 및 클러스터링을 통한 분산 데이터 스토리지, 수직 및 수평 스케일링을 지원합니다. | 클러스터링 및 복제를 통해 분산 컴퓨팅을 지원합니다. 그러나 전통적으로 분산 아키텍처를 지원하도록 설계되지 않았기 때문에 확장 성이 떨어지고 유연성이 떨어집니다. |
| 내결함성 | 데이터 복제로 인해 내결함성과 고 가용성이 내장되어 있습니다. | 복제, 백업 및 복구 메커니즘을 사용합니다. 그러나이를 위해 설계되었으므로 응용 프로그램 개발 중에 재해 복구 메커니즘과 같은 추가 조치를 구현해야 할 수도 있습니다. |
| 데이터 파티셔닝 | 샤딩과 복제를 통해 이루어집니다. | 테이블 기반 파티션 및 파티션 가지 치기(pruning)를 지원합니다. |
| 데이터를 객체 매핑 | JSON 문서, 광역 저장소 또는 키-값 쌍과 같이 다양한 방식으로 —으로 데이터를 저장합니다. ODM (객체 데이터 매핑) 프레임 워크를 통해 추상화를 제공하여 객체 지향 방식으로 NoSQL 데이터를 처리합니다. | 데이터베이스 열과 객체 지향 응용 프로그램 코드간에 완벽하게 통합되도록 데이터 대 객체 매핑에 더 의존합니다. |
7. NoSQL 사용 사례
- 실시간 분석, 컨텐츠 관리, IoT 애플리케이션, 권장 시스템, 사기 탐지, 제품 카탈로그 관리 등
- 빠르게 진행되는 민첩한 개발
- 구조화 및 반 구조화 된 데이터 저장
- 방대한 양의 데이터
- 스케일 아웃 아키텍처 요구 사항
- 마이크로 서비스 및 실시간 스트리밍과 같은 최신 애플리케이션 지원